

Intended Audience
This article is written by a software developer for anyone who is interested in the technical aspects of modern web browsers. Readers do not need any pre-knowledge to understand the content of the article. All you need to know is overview of browser (Browser Fundamentals | Part-2) and basics of HTML & CSS.
- Browser Fundamentals | Part-1 (Why and what do we need to know about browsers?)
- Browser Fundamentals | Part-2 (Technical overview of any browser)
- Browser Fundamentals | Part-3 (Networking Engine)
- Browser Fundamentals | Part-4 (Rendering Engine)
- Browser Fundamentals | Part-5 (Javascript Engine)
- Browser Fundamentals | Part-6 (Browser Engine)
Content
- Introduction
- Inside Rendering Engine
- Step I : Parse (HTML & CSS)
- Step II : Render Tree
- Step III : Layout
- Step IV : Paint
- Conclusion
Introduction
The rendering engine of a web browser, renders or displays the requested content on to the browser canvas/window. It gets the requested content from the networking engine.
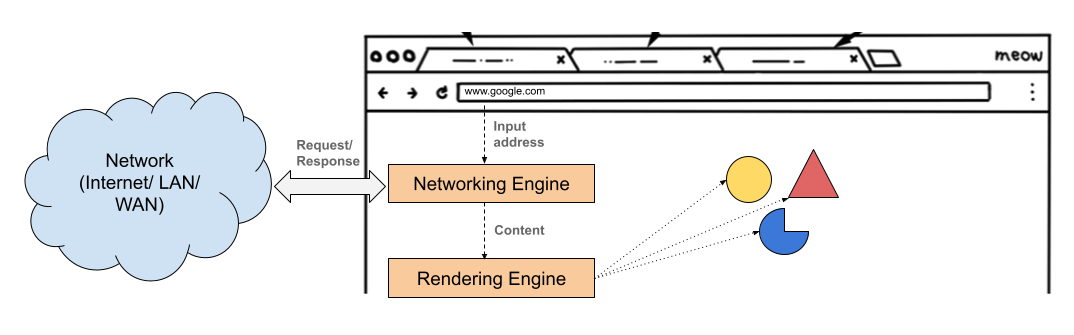
There are many types of content that can be fetched from networking engine, but not all content is fed to rendering engine. For example, .js, .json, .csv, .pdf, etc. PDFs documents are displayed using PDF viewer plug-in. For simplicity, we will discuss only the main content types which is fed to rendering engine, that is HTML(.html), CSS(.css) and Images(.png/jpeg).
- The rendering engine of a web browser, renders or displays the requested content on to the browser canvas/window.
- There are many types of content that can be fetched from networking engine, but not all content is fed to rendering engine.
Inside Rendering Engine
Now lets see what is inside rendering engine. Like networking engine, the implementation of rendering engine is different for different manufacturers. But the basic flow is same for all. It contains three crucial steps, Parse, Layout and Paint
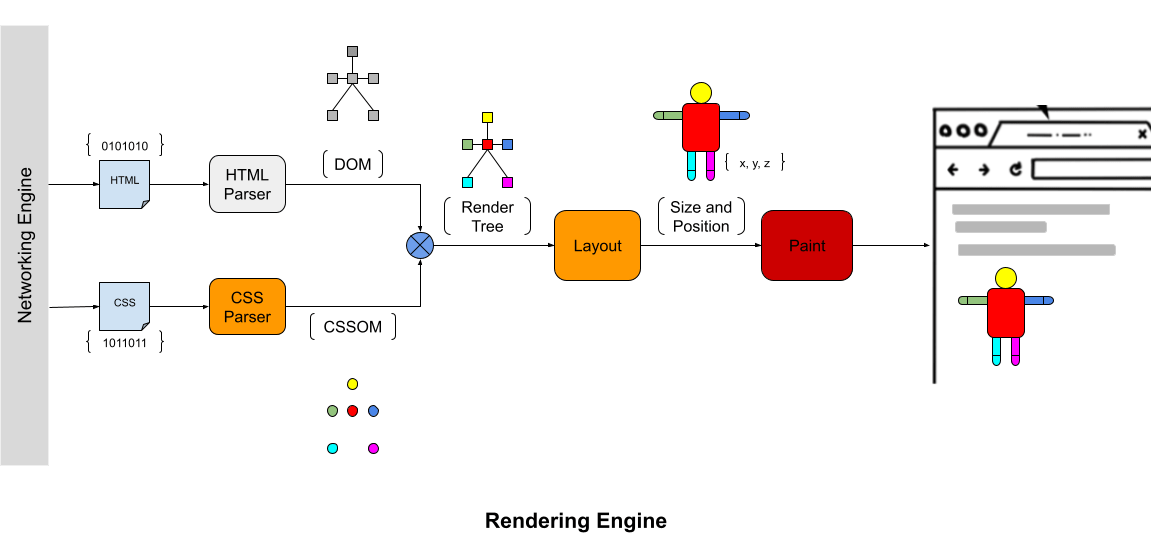
The HTML and CSS files received from the networking engine, is processed through the rendering engine before painting to the browser's window. The HTML and CSS raw data is parsed via HTML parser and CSS parser respectively to generate two tree models for completely different purposes that is, Document Object Model (DOM) and CSS Object Model (CSSOM). Then browser combines these two trees (DOM & CSSOM) and creates a Render Tree. This tree contains the information about all the visible elements to render on the screen. But this render tree lacks the exact size and position information about the element. This is the responsibility of Layout step in rendering engine. After calculating the information about the size and location, the actual step of paint starts. The Paint step does not calculate anything. Its only job is to print/render/paint on the browser's screen.
If you are a frontend developer you must have come across the term WebKit while debugging CSS related issues. This WebKit is nothing but a Rendering Engine. Here are some names of rendering engine used by different browsers:
- Internet Explorer : Trident (proprietary)
- Edge : EdgeHTML (proprietary, a fork of Trident)
- Firefox : Gecko
- Safari : WebKit (Open source)
- Chrome : Blink (a fork of WebKit)
Step I : Parse
The parsing step of the rendering process on any browser is defined by the below standards: HTML Parser: whatwg.org CSS Parser: w3.org
Since, basic steps are identical in both HTML & CSS parser, we represented both in a single diagram below:
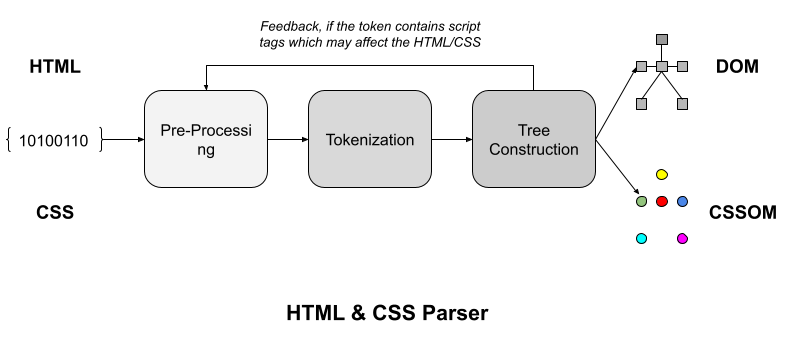
Pre-Processing
Before giving the input to tokenization stage, the input stream is first processed to make it suitable for tokenization. We will not go deep into the HTML/CSS parsers but touch the surface for this article. If you want to learn more about the parsing methods, visit the links above. Firstly, the raw input stream is converted into the code points. These code points are the unicode representation starting with "U+" followed by four/six hex codes. For example "🤔" is represented as "U+1F914". Secondly, normalizing newlines is another step in pre-processing stage. Thus, newlines in HTML DOMs are represented by "U+000A LF" (Line Feed) characters, instead of "U+000D CR" (Carriage Return) characters. Thirdly, it replaces any "U+0000 NULL" or surrogate code points (in the range "U+D800" to "U+DFFF") with "U+FFFD REPLACEMENT CHARACTER"
Tokenization
Tokenization stage is a two-step process. Creating a token and Emitting a token. A token is a node representation of each and every entity in the code. Apart from just representation, token also contains all the information about that node. For example, DOCTYPE tokens have a name, a public identifier, a system identifier, and a force-quirks flag. As soon as a token is emitted, it is immediately handled by the tree construction stage. The tree construction stage can affect the state of the tokenization stage, and can insert additional characters into the stream. (For example, the script element can result in scripts executing and using the DOM insertion APIs to insert characters into the stream being tokenized.)
Tree Construction
This stage receives the tokens from tokenization stage and creates a dynamically modifying DOM/CCSOM tree. The tree created from this step is available for user agent to use it for render purpose. According to the specifications defined by whatwg.org, there are set of rules known as tree construction dispatcher specific to the token received from the stream.
Subresource loading
While receiving the HTML tokens, if "img" or "link" tokens are received then a request is sent to network engine of the browser. To speed up things browser concurrently runs a "preload scanner'. This scanner peeks at tokens generated by the HTML parser and do necessary actions on a separate thread then parser. This pauses the HTML parser until the JS file is done with its task.
Blocking Parser
While receiving the HTML tokens, if "script" tokens are received, that means there is a Javascript file that needs to be downloaded and execute it. This step can be a blocking step as the javascript can contain statements that may change the DOM/CSSOM structure. This step is represented as a feedbak loop in the last diagram.
Conclusion of parser
If the code is:
A<script>
var text = document.createTextNode('B');
document.body.appendChild(text);
</script>C
The HTML parser will create a tree as below:
Three Text nodes; "A" before the script, the script's contents, and "BC" after the script (the parser appends to the Text node created by the script).
Step II : Render Tree
The creation of separate DOM & CSSOM trees in previous step, results in a well defined parent child relationships of various nodes along with rich mata information about structure and style respectively. But both as individually lacks complete information needed by browser to render on the screen. While DOM & CSSOM trees are being constructed, the browser constructs another tree, the Render Tree.
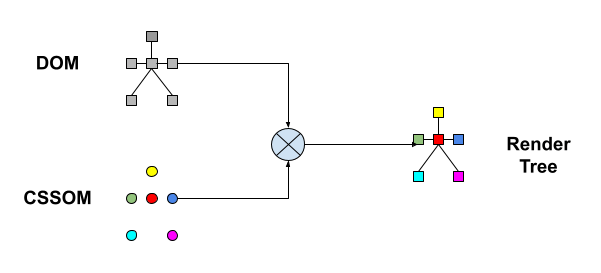
The render tree is the visual representation of the document. The purpose of this tree is to enable painting the contents in their correct order. Each element/node in the render tree called as render object. Don't get confuse, if you find different name for it somewhere else. For example, Firefox calls the elements in the render tree "frames". WebKit uses the term renderer or render object.
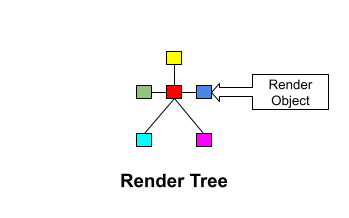
Render object has all the visual information and knows how to lay itself and its children on the screen. For example the base class of render object of WebKit is defined as following:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Each render object represents a rectangular area usually corresponding to a node's CSS box, as described by the CSS spec. It includes geometric information like width, height and position.
The box type is affected by the "display" value of the style attribute that is relevant to the node. Here is WebKit code for deciding what type of render object should be created for a DOM node, according to the display attribute:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
DOM Tree vs Render Tree
All the nodes in the render tree are from DOM tree, but not all nodes in the DOM tree maps to nodes in the render tree. The relation is not at all one-to-one. As a thumb rule, we can say that Non-visual (default or through styling) DOM elements will not be inserted in the render tree. For example "<head>" element, any element with "display: node;", etc
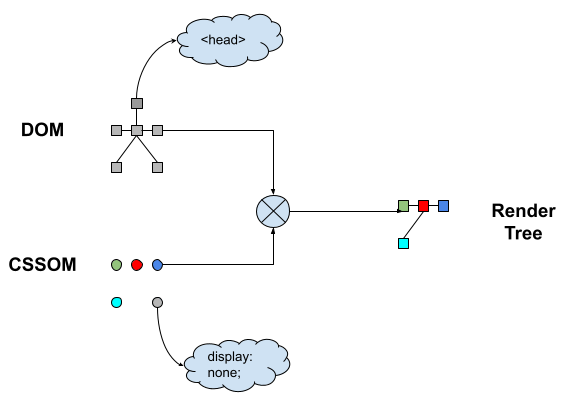 Here is the example of full DOM and render tree:
Here is the example of full DOM and render tree:
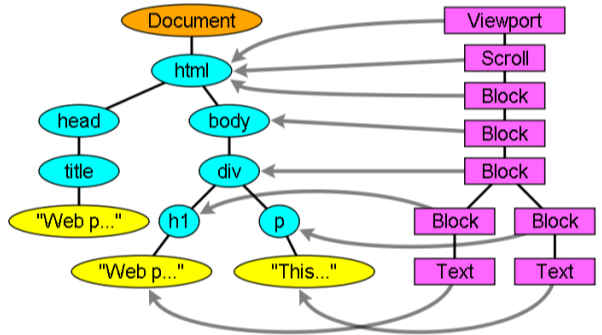 Now the render tree created, moves to next step Layout!
Now the render tree created, moves to next step Layout!
Step III : Layout
When nodes are added to the render tree, it does not have a position and size. Calculating these values is the purpose of this Layout stage. The base for size is provided by the render object itself, but the base for position is provided by the browser's view port (visible part of a browser). The position is always relative to top-left coordinates of the view port.
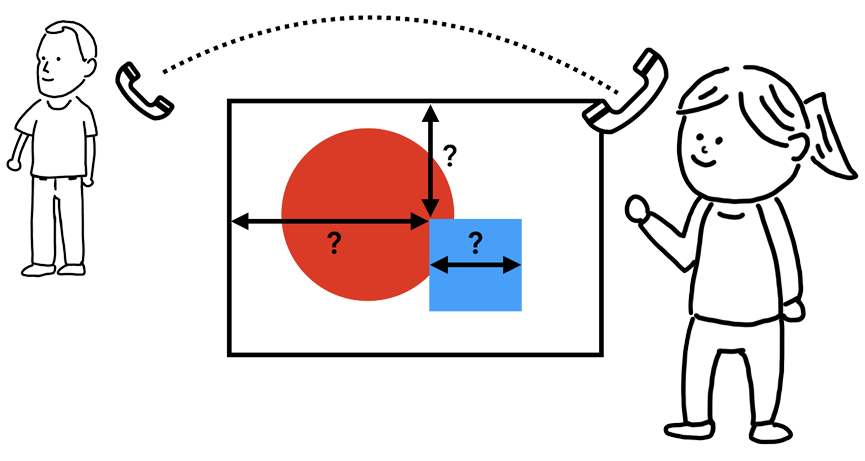 Photo Source: Google Developers
The layouting, proceeds left-to-right, top-to-bottom through the document. Also most of the time, the position and size is calculated in a singles pass with some exceptions (HTML tables may require more than one pass). This "layout" method is defined in each and every render object. Each render object invokes the layout mentod of its children the need layout.
Photo Source: Google Developers
The layouting, proceeds left-to-right, top-to-bottom through the document. Also most of the time, the position and size is calculated in a singles pass with some exceptions (HTML tables may require more than one pass). This "layout" method is defined in each and every render object. Each render object invokes the layout mentod of its children the need layout.
{kind=link}
The Layout Process
Below is the basic step involved in layout stage, though it may differ slightly based on the browser (rendering engine):
- The parent render object calculates its own width.
-
Parent render object goes over children and:
- Place the child render object and sets its coordinates (x, y).
- Calls child renderobject's layout method if needed, which calculates the child's height.
- Parent uses children's accumulative heights and the heights of margins and padding to set its own height–this will be used by the parent render object's parent.
- Sets its dirty bit to false.
Step IV : Paint
From layout stage, we got all the information needed to render the element on the screen. Still nothing is yet printed on the screen. For painting the ready elements to the browser's screen, we have last stage in the rendering engine that is Paint!
Finally the time has come 😀, when we finally paint the display ready elements to the screen. But spart form just painting, this stage also have to judge in what order you paint them. For example, z-index might be greater for elements which appear before in the render tree.
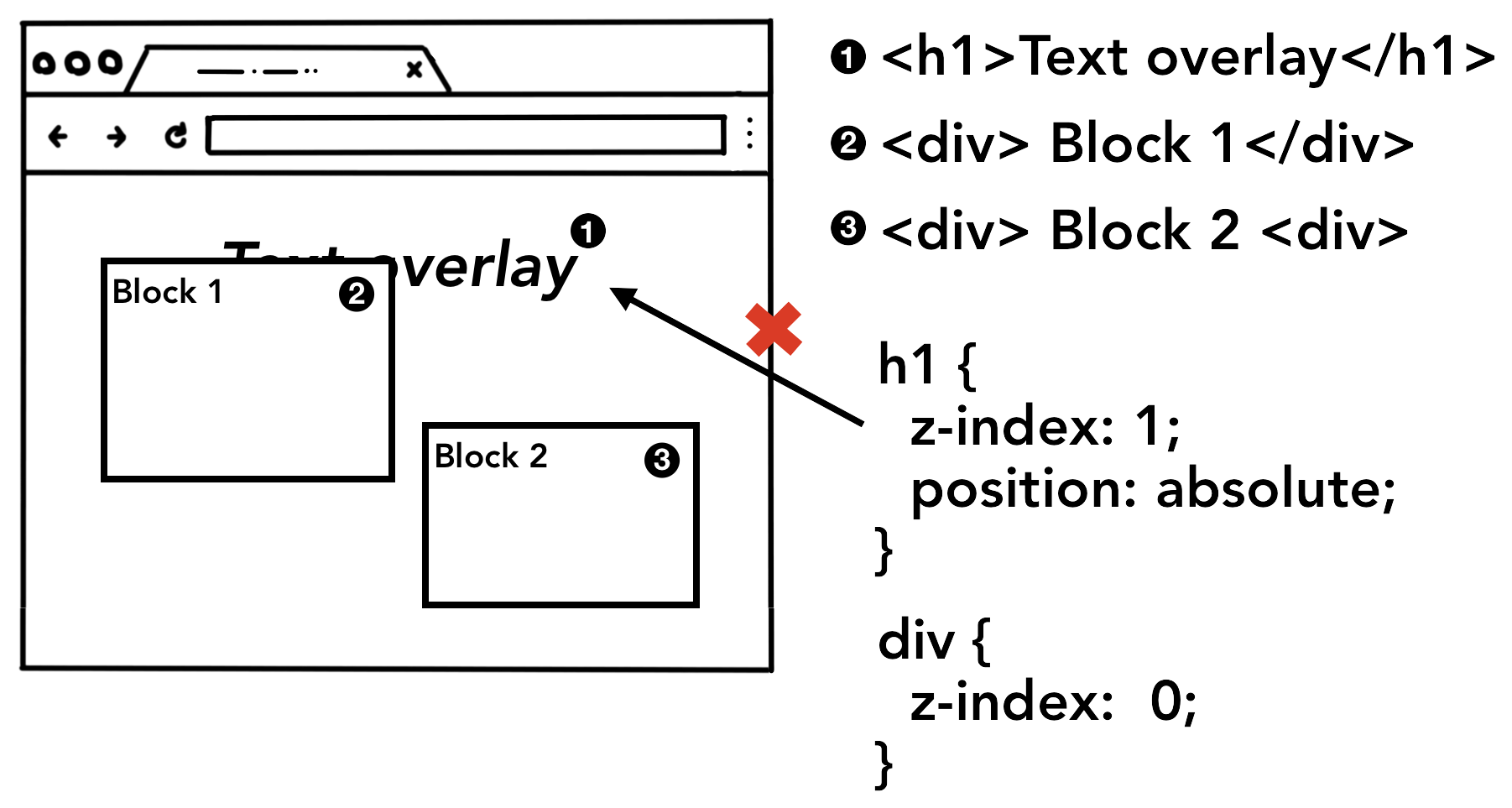 Photo Source: Google Developers
Photo Source: Google Developers
{kind=link}
In this stage the render object go through two steps: Paint Records & Compositing. First, browser iterate through the render tree and create paint records. Secondly, rasters the page with the paint record with advanced technique known as Compositing.
Paint Record
Paint record is a check point of the painting process. This includes the actual stacking order of render object.
- Background color
- Background image
- Border
- Children
- Outline
Compositing
Compositing is a technique, how browsers actualy paints to the screen. It is an advaced version of naive rastering process. This technique divides indiviual elements into layers and creates a Layer Tree. Once the layer tree is created and paint orders are determined, the compositor thread then rasterizes each layer. A layer could be large like the entire length of a page, so the compositor thread divides them into tiles and sends each tile off to raster threads. Raster threads rasterize each tile and store them in GPU memory. The compositor thread can prioritize different raster threads so that things within the viewport (or nearby) can be rastered first. A layer also has multiple tilings for different resolutions to handle things like zoom-in action. Once tiles are rastered, compositor thread gathers tile information called draw quads to create a compositor frame. Draw quads Contains information such as the tile's location in memory and where in the page to draw the tile taking in consideration of the page compositing. Compositor frame A collection of draw quads that represents a frame of a page. A compositor frame is then submitted to the browser process via IPC. At this point, another compositor frame could be added from UI thread for the browser UI change or from other renderer processes for extensions. These compositor frames are sent to the GPU to display it on a screen. If a scroll event comes in, compositor thread creates another compositor frame to be sent to the GPU.
- Converting an information into pixels on the screen is called rasterizing.
- The benefit of compositing is that it is done without involving the main thread.
- Compositor thread does not need to wait on style calculation or JavaScript execution.
Result
The result is something like this:Conclusion
In conclusion, now we completed the rendering engine working. Here are key points to remember:
- Rendering engine takes inputs from networking engine and displays on the browser.
- Parse, Render Tree, Layout, Paint & Compositing are key stages of a rendering engine.
- DOM/CSSOM tree does not have one-to-one mapping to render tree (it can be one-to-many).
- Compositor thread does not need to wait on style calculation or JavaScript execution.
Links & References
- https://developer.mozilla.org/en-US/docs/Glossary/Trident
- https://en.wikipedia.org/wiki/Trident_(software)
- https://developers.google.com/web/updates/2018/09/inside-browser-part3
- https://html.spec.whatwg.org/multipage/parsing.html
- http://taligarsiel.com/Projects/howbrowserswork1.htm
- https://blog.logrocket.com/how-browser-rendering-works-behind-scenes/
- https://source.chromium.org/chromium/chromium/src/+/master:third_party/blink/renderer/core/paint/#Overview
About Author
I love to shape my ideas into a reality. You can find me either working on a project or having a beer with my close friend. :-)